What is predictive Analytics ?
Predicting the future is what data was made for.

Predictive analytics, AKA prediction analytics, is a term used for analytical and statistical techniques that assist in predicting future changes, events, and behavior for a variety of topics.
Companies today are swamped with data stored and collected from various mediums and sources . Predictive analytics provides great help to analyze and understand statistical techniques that would assist in predicting future plot.
Many businesses employ predictive analytics to optimize operations, improve marketing campaigns, and increase revenue. Predictive models help companies attract, retain and nurture customers.
Companies use predictive analytics to forecast future events based on past data. It helps them mitigate risks and identify opportunities, such as estimating the lifetime value of customers or planning for economic downturns.
With customer expectations touching the sky to increased competition, businesses seek an edge in bringing products and services to stand apart in the market and deliver incredible customer experiences. Where customers expect businesses to read their minds and surprise them with something new, businesses are always one step ahead to do so.
The predictive analytics process :
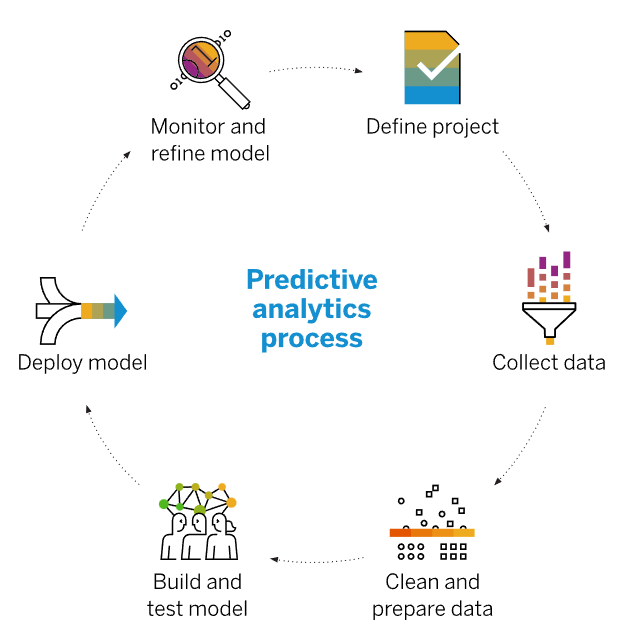
Define Project- Like all analytical endeavors, prediction begins with planning. Teams scope out the needs of each business unit that’s involved, such as product, marketing, customer support, or analytics. What are their goals? What questions do they hope to answer? How do they prefer to view data? What sources are they most interested in? Step one is to make a tracking plan.
Collect Data- Data collection comes second, and it’s the most time-consuming step. Teams identify their data sources, verify that the data is clean and up-to-date, and connect those sources to an analytics tool. Because most data decays with time, and information like customer records can expire every few years, this stage often suffers from mission creep. Solving one data issue sometimes exposes more data issues and the project balloons beyond its scope.
Once the data is integrated, teams are able to view data from multiple sources within the analytics tool interface. A SaaS company, for example, can connect its CRM data, product data, website data, call center notes, and third-party data providers, and begin inferring how pillars of its business affect one another.
Clean & Analyze- Clean, prepare, and integrate your data to get it ready for analysis. Remove unwanted observations from your dataset, including duplicate observations or irrelevant observations. Duplicate observations will happen most often during data collection.
Build and test your model- Build your predictive model, train it on your data set, and test the same to ensure its accuracy. It may take multiple iterations to generate an error-free model. The building of a data model is a critical step in the design of the data warehouse.
Data modelling is the process used to shape on how data is stored. The term ‘model’ is little misunderstood. It isn’t necessarily a computer program — it’s just an equation that summarizes a relationship and suggests an outcome. For example, saying ‘If X occurs, Y is twice as likely to occur.’ Any algebraic equation is, technically, a model.
Examples of predictive models:
- SaaS: Leads that visit 10+ web pages are 50 percent more likely to purchase.
- E-commerce: A shopper that abandons an item is 3x more likely to click an ad.
- Media & entertainment: Listeners that like heavy metal are 2x more likely to enjoy rock.
For the creation of any database, the data model is considered a logical structure for creating a database. The data model includes entities, attributes, constraints, relationships, etc. The data model is just a shell without populated data. It is nothing more than a drawing.
The most common types of models include:
- Decision trees use a virtual flowchart to list all possible outcomes for an event. Decision trees are the simplest method for prediction, and are especially useful when a model has missing values or unknown variables.
- Regression analyses quantify the relatedness of multiple variables and express it as a percentage. Variables can be loosely correlated, highly correlated, or not correlated at all.
- Machine learning models rely on a neural network, or an algorithm that mimics a human brain, to discover the relationship between variables. Neural networks are powerful, but they can’t always explain why they reached a particular conclusion.
Deploy- If a model works, teams use it. But they should always test its effectiveness with a sample population before rolling it out widely, the same way they A/B test new product designs before launch. Good old-fashioned human judgement is an effective quality check to make sure the model results and recommendations make sense. If they seem particularly far off the mark, it’s an opportunity for teams to double-check their data, model, and underlying assumptions.
Monitor & Refine- What works in a test environment very rarely works in reality without adjustment. But real performance data from real users is the first step toward improving the model so it produces reliably useful results.
Predictive analytics versus prescriptive analytics:
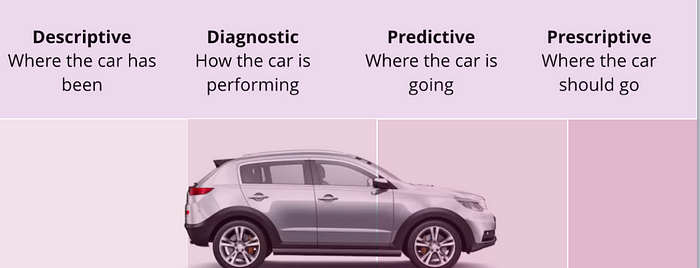
Analytics fall into four categories based on the degree to which they are focused on the future. Predictive analytics and prescriptive analytics are very similar, except that prescriptive analytics go one step further to recommend or trigger an action, as with a self-driving car. Predictive analytics software is used to forecast while prescriptive analytics software is used to advise.
- Descriptive analytics provide data about the past.
- Diagnostic data display data in real time.
- Predictive analytics forecast future events using past data.
- Prescriptive analytics forecast future events and recommend actions.
Predictive analytics challenges :
The only thing growing faster than the use of predictive analytics is its misuse. As big data, fast computing, and user-friendly software have grown cheaper, all manner of companies now attempt to prognosticate the future. Despite abundant data, most people are no different that Croesus, and base their predictions on assumptions. Companies hire on the assumption that their revenue will continue to grow, invest on the assumption that the market won’t change, and launch products on the assumption that they understand what customers want. Assumptions are like earthquake fault lines that threaten the models that rest upon them. But, even the worst assumptions can be neutralized, if accounted for.
Assuming the future will be like the past
Sometimes, events occur that have never happened before. These are called black swan events, based on the idea that no amount of observing white swans can confirm the hypothesis that all swans are white. It’s only when someone sees a black swan that they know the hypothesis is untrue. But because black swans never occurred in past data, a predictive model could never has foretold it.
This presumption of continuity is the most common false assumption in business. That’s why earlier it was famously predicted that the iPhone would never succeed, Oracle was slow to recognize the opportunity of cloud-based software, and Blockbuster failed to pivot to streaming video. Their executives weren’t wrong — according to the past data.
As the aphorism goes, prediction is difficult — especially about the future. Companies can make their predictions better by investing in the teams, tools, and training that help them benefit from the upsides of forecasts without suffering the downsides.
With the right setup and a healthy sense of constructive paranoia, prediction is possible.

